All of our documentation in the LymeStack Product Manual is authored using standard text-based Markdown files using Visual Studio Code and the Markdown Preview Enhanced VS Code plug-in, which offers a preview of the Markdown output to the side while editing.
I have a centrally located README.md file that serves as my document index containing a link to every other markdown file in the folder or any subfolders. We used this documentation to submit as part of our provisional patent application that we filed with the US Patent and Trademark Office (USPTO). In order to submit the document to the USPTO, we first had to convert it to a combined PDF. In order to do this, we execute this Python script in the same folder as the README file:
import os
import sys
import markdown2
def adjust_image_paths(content, current_file_dir, output_base_dir):
"""
Adjust relative image paths to be relative to the output base directory and use forward slashes.
"""
lines = content.split('\n')
for i, line in enumerate(lines):
if '](' in line:
#if ' + 2
end_link = line.find(')', start_link)
relative_path = line[start_link:end_link]
if not os.path.isabs(relative_path):
# Calculate the relative path from the current file directory to the image
image_path = os.path.normpath(os.path.join(current_file_dir, relative_path))
relative_to_output = os.path.relpath(image_path, output_base_dir)
# Convert backslashes to forward slashes
relative_to_output = relative_to_output.replace('\\', '/')
lines[i] = line[:start_link] + relative_to_output + line[end_link:]
return '\n'.join(lines)
def assemble_markdown_files(index_file, output_file_base):
markdown_content = ""
toc_content = ""
base_path = os.path.dirname(os.path.abspath(index_file))
output_base_dir = os.path.dirname(os.path.abspath(output_file_base + '.md'))
with open(index_file, 'r') as file:
lines = file.readlines()
for line in lines:
if ' [' in line:
start_link = line.find('(') + 1
end_link = line.find(')')
file_link = line[start_link:end_link].strip()
file_path = os.path.normpath(os.path.join(base_path, file_link))
# Generate clean anchors for ToC links
anchor_link = f'#{os.path.basename(file_link).replace(".md", "").replace(" ", "-").lower()}'
toc_line = line.replace(file_link, anchor_link)
toc_content += toc_line
# Check file type and skip non-markdown files
if file_link.lower().endswith('.md') and os.path.exists(file_path):
with open(file_path, 'r') as infile:
file_contents = infile.read()
file_contents = adjust_image_paths(file_contents, os.path.dirname(file_path), output_base_dir)
file_contents = file_contents.replace("\n#", "\n##") # Downgrade headers
markdown_content += f"\n<a id='{os.path.basename(file_link).replace('.md', '').replace(' ', '-').lower()}'></a>\n\n----\n\n"
markdown_content += file_contents + '\n'
elif not file_link.lower().endswith('.md'):
toc_content += f" (External file not included in compilation)\n"
else:
markdown_content += f"# File not found: {file_link}\n\n"
else:
toc_content += line
markdown_content += line
complete_markdown = toc_content + markdown_content
with open(output_file_base + '.md', 'w') as outfile:
outfile.write(complete_markdown)
if __name__ == "__main__":
index_filename = 'README.md'
output_filename_base = 'Complete'
if len(sys.argv) > 1:
index_filename = sys.argv[1]
if len(sys.argv) > 2:
output_filename_base = sys.argv[2]
assemble_markdown_files(index_filename, output_filename_base)
To use this script, from the folder where the script and readme file and other markdown files reside, run the following command in your terminal window or command prompt:
python assemble-mardown-files.py
You will see a new file created as a result of running the above command called Complete.md. If you open that file using the VS Code plugin and right-click anywhere in the preview window, you will see an "Open in Browser" option.
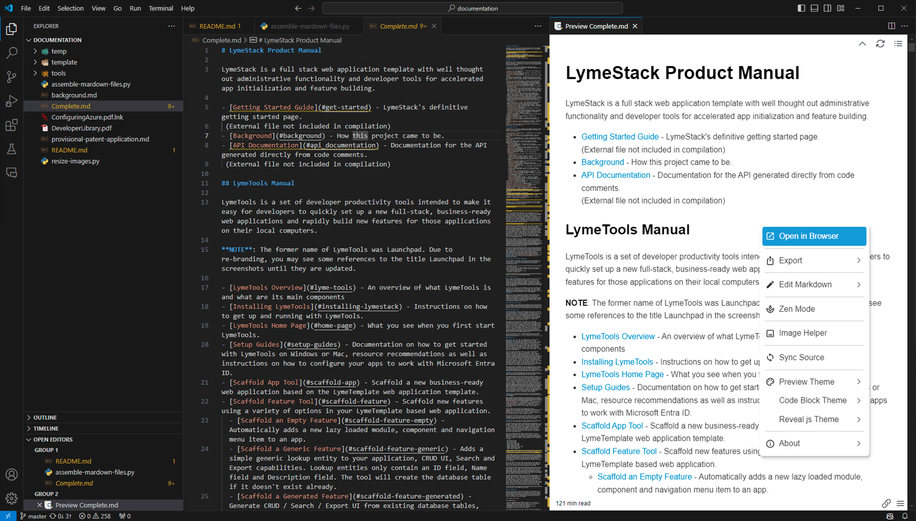
Clicking that option will open the combined PDF as and HTML web page. From there, you can use your browser's print feature to print this output to a PDF document, which will result in a professional looking and navigable / searchable PDF output. This final output was what was submitted to the USPTO as a specification document.